DOC_ID: CAR_CHART.TXT
Car
Chart.
AI-powered auction analytics & canonical vehicle data platform. A full-stack data platform designed to automate vehicle research, normalize auction data, and surface market insights for car buyers — combining AI-driven research, human-in-the-loop validation, and large-scale auction scraping to build a canonical vehicle database.
Why This Exists
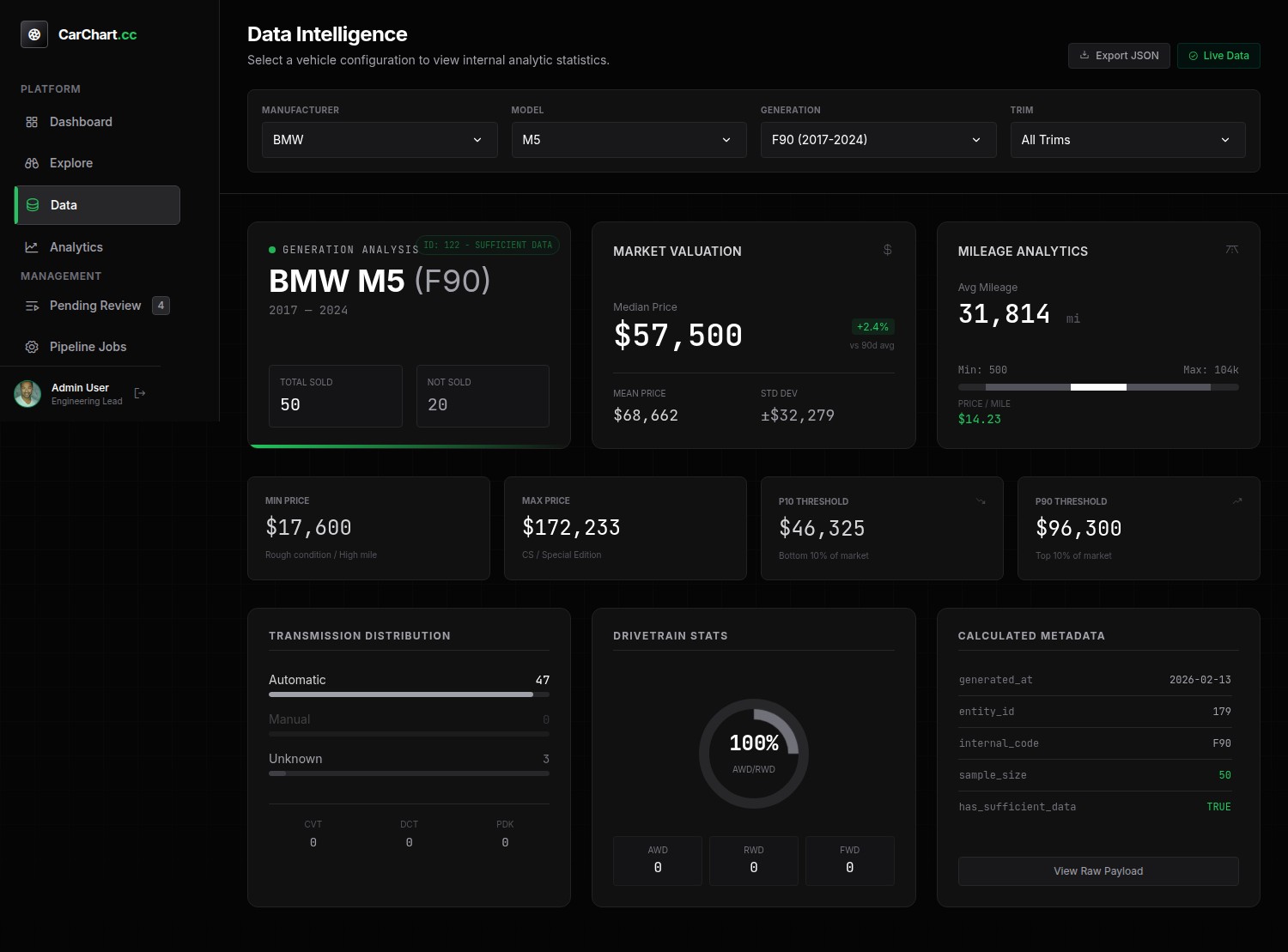
The car buying experience is typically a long,frustrating, manual process. Online auction platforms aim to solve this by providing quick, convient auctions for enthusiast vehicles. However, this results in a new problem: Users must decided which auctions are worth their time and effort. Car auction data is messy. Listings vary wildly in naming, trim details, and structure — making meaningful analytics nearly impossible without a clean, canonical dataset. Building that dataset manually (Make → Model → Generation → Trim) is slow, error-prone, and doesn’t scale.
The challenge: How do you build a reliable, evolving vehicle hierarchy while ingesting thousands of inconsistent auction listings?
Architecture Overview
Car Chart is designed as a modular, containerized system with clear separation between orchestration, background workers, and human review.
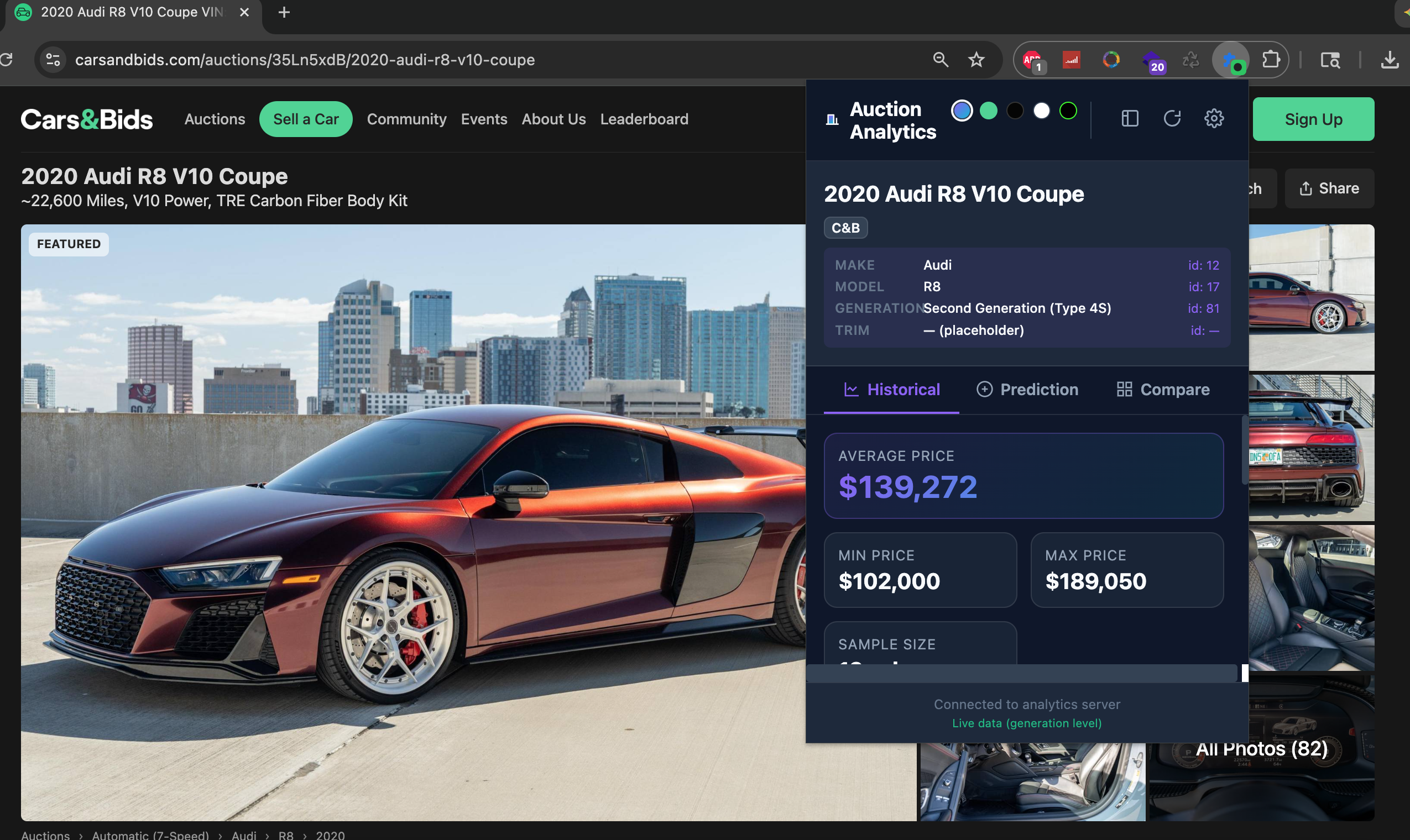
- AI Research Agent — Discovers vehicle models, generations, and trims using LLMs and structures the results into staging tables.
- Human-in-the-Loop Review UI — A web dashboard for approving, editing, or rejecting AI-generated data before it enters the canonical dataset.
- Queue-Based Scraper System — Worker containers claim jobs from a database-backed queue and scrape auction data asynchronously.
- Canonical Database Layer — A normalized PostgreSQL schema that enforces consistency across makes, models, generations, trims, and auctions.
The API and worker services share a database and log volume — eliminating unnecessary network coupling while maintaining observability.
Key Technical Decisions
Human-in-the-Loop by Design
AI accelerates discovery, but correctness matters. All AI-generated vehicle data enters staging tables and must be explicitly reviewed before promotion to canonical records. This prevents data drift while still allowing rapid expansion.
Matching & Deduplication Logic
To avoid duplicates and fragmentation, the system performs automated matching using internal generation codes (e.g. E46, F80), normalized string comparisons, and fuzzy matching thresholds for trims and aliases. Suggested matches are presented during review — speeding approval without sacrificing accuracy.
Scalable Scraping Architecture
Queue-based job execution using database locks; isolated worker containers with supervised scraper processes; per-auction error handling to ensure long-running jobs continue safely; optional extraction of bids, comments, and metadata. Scraping scales independently from the UI and API layer.
Role & Ownership
Solo architect, solo builder — system design, data modeling, AI orchestration, worker design, scraper engine, admin UI, and matching logic.